Kubernetes Clusters in the VPC
 Clients can now easily launch Kubernetes instances from our Virtual Private Cloud.
Clients can now easily launch Kubernetes instances from our Virtual Private Cloud.
This can be useful for users looking to comfortably manage a large number of application containers. Kubernetes provides an environment that scales, automatically restores, and balances loads for containers launched inside clusters.
Since the Virtual Private Cloud is built on OpenStack, we use OpenStack Magnum. This lets us quickly create private Kubernetes clusters with a custom number of nodes.
VPC users can already create multiple independent clusters in a project. Here, custom virtual machines serve as the cluster’s nodes.
In this article, we will discuss the main Kubernetes cluster objects and look at a few examples of how Magnum can be used to create clusters.
Creating and Managing Kubernetes Clusters
Currently, Kubernetes clusters can only be created from console tools or the OpenStack API in zones ru-1a and ru-1b (St. Petersburg).
Before we get started, we will need to do the following:
- Create a new VPC project or designate an existing project
- Create a user with an SSH key
- Add the user to the designated project on the project management page
- Open the project and download the access file from the Access tab
- Install the openstack console client with the python-magnumclient library
- Install the kubectl console client
Please note that the openstack console client requires the python-magnumclient library to create Kubernetes clusters.
To install the openstack client and necessary plugins in Ubuntu/Debian:
$ sudo apt update $ sudo apt -y install curl python-pip python-dev python3-dev git libxml2-dev libxslt1-dev python-openssl python3-openssl python-pyasn1 libffi-dev libssl-dev build-essential $ sudo pip install -UI pbr setuptools pytz $ sudo pip install -UI git+https://github.com/openstack/python-openstackclient $ sudo pip install -UI git+https://github.com/openstack/python-magnumclient
To install the openstack client and required plugins in Fedora/CentOS:
$ sudo yum -y install python-pip gcc libffi-devel python-devel libxslt-devel openssl-devel git libffi-devel $ sudo pip install -UI pbr setuptools pytz $ sudo pip install -UI git+https://github.com/openstack/python-openstackclient $ sudo pip install -UI git+https://github.com/openstack/python-magnumclient
To manage Kubernetes objects, you will need the kubectl console client. Installation instructions for different operating systems can be found in the official documentation.
To create a cluster, you will have to create or use an existing:
- cluster template
- flavor (set of virtual machine CPU and RAM parameters)
Users can create their own templates and flavors or use existing public templates.
You will also need to determine the access zone, cluster volume type, and number of nodes. Please note that we do not currently support multi-zone clusters. All network volume types (fast, universal, basic) are available.
You can find more information about volume types in our knowledge base.
You can launch a different number of master and minion nodes. Cluster management elements, like controller-manager, scheduler, and api, are launched on master nodes; kubelet, kube-proxy, and application containers are launched on minions. More information about what can be launched on cluster nodes can be found in the official documentation.
To access nodes via SSH, you will need a previously generated SSH key. For our examples, we will use a key with the name ssh-test.
We will use a public cluster template and flavor, fast disk, and the ru-1b zone.
In our cluster, we initially launched 2 masters and 3 minions.
To check the given parameters, we use the openstackclient command and access file that we downloaded (rc.sh):
# Launch the project access file to set the required parameters. $ source rc.sh # Configuration of server we will use for all cluster nodes $ openstack flavor show BL1.2-4096 -c ram -c vcpus +-------+-------+ | Field | Value | +-------+-------+ | ram | 4096 | | vcpus | 2 | +-------+-------+ # Fast volume in zone ru-1b $ openstack volume type show fast.ru-1b -c name +-------+------------+ | Field | Value | +-------+------------+ | name | fast.ru-1b | +-------+------------+ # Available Kubernetes cluster templates $ openstack coe cluster template list -c name +---------------------------------------+ | name | +---------------------------------------+ | kubernetes-nofloatingips-ru-1b-v1.9.3 | | kubernetes-nofloatingips-ru-1b-v1.9.6 | | kubernetes-nofloatingips-ru-1b-v1.9.9 | | kubernetes-floatingips-ru-1b-v1.9.3 | | kubernetes-floatingips-ru-1b-v1.9.6 | | kubernetes-floatingips-ru-1b-v1.9.9 | +---------------------------------------+
In our example, we will choose the second cluster template. This will not create a publicly accessible floating IP address for each node, since we have no real need for them at this time.
# Create a Kubernetes cluster named test-cluster # For keypair we use the name of the key we created earlier $ openstack coe cluster create --cluster-template kubernetes-nofloatingips-ru-1b-v1.9.9 --master-count 2 --node-count 3 --keypair ssh-test --master-flavor BL1.2-4096 --flavor BL1.2-4096 test-cluster
Please note that we chose the same configuration for different nodes (the master-flavor and flavor parameters), but you can choose different configurations depending on your cluster’s requirements. These can be changed even after the nodes have been created.
It is also worth nothing that when creating a cluster with multiple master nodes, a load balancer will automatically be created for Kubernetes API access.
A Kubernetes cluster will appear in our project a few minutes later. The new virtual machines, disks, and network objects will be visible in the project control panel.
You can check the status of your cluster using openstackclient:
$ openstack coe cluster list +--------------------------------------+--------------+----------+------------+--------------+--------------------+ | uuid | name | keypair | node_count | master_count | status | +--------------------------------------+--------------+----------+------------+--------------+--------------------+ | fb363e6f-7530-44d9-ad12-88721a51732c | test-cluster | ssh-test | 2 | 3 | CREATE_IN_PROGRESS | +--------------------------------------+--------------+----------+------------+--------------+--------------------+
When the cluster status changes to CREATE_COMPLETE, you can mange its objects in kubectl by downloading a configuration file with the following command:
$ mkdir -p ~/test-cluster $ openstack coe cluster config test-cluster --dir ~/test-cluster
You can then use kubectl to interact with the cluster:
$ export KUBECONFIG=~/test-cluster/config $ kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-785dcf9c58-j4kj6 1/1 Running 0 5m kube-system heapster-6846cdc674-6rt85 1/1 Running 0 5m kube-system kube-dns-autoscaler-6b94f7bbf8-sskg5 1/1 Running 0 5m kube-system kubernetes-dashboard-747575c864-5st5l 1/1 Running 0 5m kube-system monitoring-grafana-84b4596dd7-brvp9 1/1 Running 0 5m kube-system monitoring-influxdb-c8486fc95-w4ltf 1/1 Running 0 5m kube-system node-exporter-test-cluster-s2zyasp62pii-minion-0 1/1 Running 0 2m
If necessary, you can increase or decrease the number of minions in openstackclient by assigning a new value to the node_count parameter:
$ openstack coe cluster update test-cluster replace node_count=4
Basic Kubernetes Cluster Objects
Pods
Although we commonly associate Kubernetes with containers, the most fundamental Kubernetes object is the pod.
Pods are sets of Linux kernel namespaces and network stack configurations, which let containers compile in a single entity.
More often than not, one application container is launched inside a single pod. If need be, you can launch multiple containers inside a single pod, which may be useful if you need to grant access from one container to another over localhost or launch multiple containers on one host.
All containers launched in a single pod will share a hostname, IP address, routing table, and volumes.
It is worth noting that when scaling the number of instances of an application in Kubernetes, you also have to increase the number of pods, and not containers in a particular pod.
Read more about pods in the official documentation.
How we create a basic pod with Nginx using a YAML description:
# nginx-basic.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: library/nginx:1.14-alpine
ports:
- containerPort: 80
We can create our pod using kubectl.
All of the examples in this article can be found in our Github group, so you do not have to create any local files, just use the file’s URL from the public repository:
$ kubectl create \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/pods/nginx-basic.yaml
Once the pod has been created, we can request a full printout of the pod’s status using the command kubectl describe:
$ kubectl describe pod nginx
Name: nginx
Namespace: default
Node: test-cluster-nd5c5y6lsfxb-minion-0/10.0.0.5
Start Time: Sun, 17 Jun 2018 12:29:03 +0000
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.100.88.9
Containers:
nginx:
Container ID: docker://6ca6383b66686c05c61c1f690737110e0f8994eda393f44a7ebfbbf2b2026267
Image: library/nginx:1.14-alpine
Image ID: docker-pullable://docker.io/nginx@sha256:944b79ca7dbe456ce72e73e70816c1990e39967c8f010349a388c00b77ec519c
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Sun, 17 Jun 2018 12:29:16 +0000
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-rp5ls (ro)
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
Volumes:
default-token-rp5ls:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-rp5ls
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 52s default-scheduler Successfully assigned nginx to test-cluster-nd5c5y6lsfxb-minion-0
Normal SuccessfulMountVolume 51s kubelet, test-cluster-nd5c5y6lsfxb-minion-0 MountVolume.SetUp succeeded for volume "default-token-rp5ls"
Normal Pulling 50s kubelet, test-cluster-nd5c5y6lsfxb-minion-0 pulling image "library/nginx:1.14-alpine"
Normal Pulled 39s kubelet, test-cluster-nd5c5y6lsfxb-minion-0 Successfully pulled image "library/nginx:1.14-alpine"
Normal Created 39s kubelet, test-cluster-nd5c5y6lsfxb-minion-0 Created container
Normal Started 39s kubelet, test-cluster-nd5c5y6lsfxb-minion-0 Started container
As you can see, the pod was launched on node test-cluster-nd5c5y6lsfxb-minion-0 and was assigned internal IP address 10.100.88.9.
Under Events, we can see the main launch events: node selection and image download.
We can access the pod and check the status of processes inside its container:
$ kubectl exec -it nginx sh
ps aux
PID USER TIME COMMAND
1 root 0:00 nginx: master process nginx -g daemon off;
7 nginx 0:00 nginx: worker process
20 root 0:00 sh
24 root 0:00 ps aux
exit
It is worth keeping in mind that IP address 10.100.88.9 will not be available to other application inside or outside the Kubernetes cluster; access to the launched Nginx instance will only be possible from within the same pod:
$ ping -c 1 10.100.88.9 PING 10.100.88.9 (10.100.88.9): 56 data bytes --- 10.100.88.9 ping statistics --- 1 packets transmitted, 0 packets received, 100% packet loss $ kubectl exec nginx -- ping -c1 10.100.88.9 PING 10.100.88.9 (10.100.88.9): 56 data bytes 64 bytes from 10.100.88.9: seq=0 ttl=64 time=0.075 ms --- 10.100.88.9 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 0.075/0.075/0.075 ms
In addition to the fact that the given IP address is only accessible from within the container, it also is not permanent. This means that if the pod is recreated, it may be assigned a different IP address.
To solve these problems, we can use an object called Service.
Services
Service lets you assign pods a permanent IP address, grant access from external networks, and balance requests between pods.
A more detailed description of Service can be found in the official documentation.
For our example, we need to delete our pod:
$ kubectl delete pod nginx
We add the necessary Service label to the pod description:
# nginx-labeled.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: webservice
spec:
containers:
- name: nginx
image: library/nginx:1.14-alpine
ports:
- containerPort: 80
We also need a Service description:
# nginx-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-nodeport
labels:
app: webservice
spec:
type: NodePort
ports:
- port: 80
nodePort: 30001
protocol: TCP
selector:
app: webservice
Next we create the pod and Service:
$ kubectl create \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/pods/nginx-labeled.yaml \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/services/nginx-nodeport.yaml
Since this Service has a NodePort type, the port we specified, 30001, will be open on all network interfaces on all cluster nodes.
This means that if we add an external IP address to any node, we will be able to access our pod with Nginx from an external network.
To access the Service without the node’s external address, we can define the type as LoadBalancer instead of NodePort.
To do that, we will need a new Service description:
# nginx-loadbalancer.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-loadbalancer
labels:
app: webservice
spec:
type: LoadBalancer
ports:
- port: 80
protocol: TCP
selector:
app: webservice
We delete the current Service and apply the new description:
$ kubectl delete service nginx-service $ kubectl create \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/services/nginx-loadbalancer.yaml
After launching the Service, Nginx will be accessible from external networks via TCP port 80. In this case, no external addresses will have to be assigned or used for node clusters. The LoadBalancer Service automatically assigns and applies an external address to your VPC project.
You can retrieve information on the external address with kubectl:
$ kubectl get service nginx-service -o=custom-columns=IP:status.loadBalancer.ingress[0].ip IP xxx.xxx.xxx.xxx
In our examples, only one Pod with Nginx was launched. To scale an application to more pods, we can use deployment.
Deployments
Deployment is a Kubernetes cluster element that allows you to scale pods and conveniently update or roll back versions for a large number of pods. ReplicaSet can also be used in place of Deployment, but this will not be used in our examples.
More information about Deployment can be found in the official documentation.
Again we have to delete our Pod (the Service does not need to be deleted):
$ kubectl delete pod nginx
We add the following Deployment description:
# nginx-1.14.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 10
selector:
matchLabels:
app: webservice
minReadySeconds: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels:
app: webservice
spec:
containers:
- name: nginx
image: library/nginx:1.14-alpine
ports:
- containerPort: 80
Next we create the Deployment object:
$ kubectl create -f \ https://raw.githubusercontent.com/selectel/kubernetes-examples/master/deployments/nginx-1.14.yaml
We set the ‘replicas’ value to 10, so 10 pods with Nginx will be created in our cluster:
$ kubectl get pods --selector app=webservice NAME READY STATUS RESTARTS AGE nginx-deployment-54bfdc4489-42rrb 1/1 Running 0 4m nginx-deployment-54bfdc4489-5lvtc 1/1 Running 0 4m nginx-deployment-54bfdc4489-g7rk2 1/1 Running 0 4m nginx-deployment-54bfdc4489-h5rxp 1/1 Running 0 4m nginx-deployment-54bfdc4489-l9l2d 1/1 Running 0 4m nginx-deployment-54bfdc4489-pjpvg 1/1 Running 0 4m nginx-deployment-54bfdc4489-q8dnp 1/1 Running 0 4m nginx-deployment-54bfdc4489-s4wzf 1/1 Running 0 4m nginx-deployment-54bfdc4489-tfxf9 1/1 Running 0 4m nginx-deployment-54bfdc4489-xjzb5 1/1 Running 0 4m
You can access the application externally using the Service object created in the previous section. Service will automatically balance requests from external networks between the 10 Nginx instances.
We can also update Nginx if need be. We update the Deployment description by changing the image version from 1.14-alpine to 1.15-alpine:
# nginx-1.15.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 10
selector:
matchLabels:
app: webservice
minReadySeconds: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
template:
metadata:
labels:
app: webservice
spec:
containers:
- name: nginx
image: library/nginx:1.15-alpine # <-- changed
ports:
- containerPort: 80
To start the pod update process, we use kubectl. Pay attention to the –record argument; this will help us easily roll back Nginx in the future:
$ kubectl apply -f \ https://raw.githubusercontent.com/selectel/kubernetes-examples/master/deployments/nginx-1.15.yaml \ --record
You can track the update process using the following command:
$ kubectl rollout status deployment nginx-deployment Waiting for rollout to finish: 4 out of 10 new replicas have been updated...
After updating each pod, Kubernetes will wait 10 seconds before moving on to the next. This corresponds to the minReadySeconds parameter in the Deployment description, which we set to 10.
When the update is complete, all pods for Deployment will switch to active:
$ kubectl get deployment --selector app=webservice NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE nginx-deployment 10 10 10 10 23m
We can roll back our application if something does not work right. To do this, we will need to choose the correct Deployment revision.
$ kubectl rollout history deployment nginx-deployment deployments "nginx-deployment" REVISION CHANGE-CAUSE 1 <none> 2 kubectl apply --filename=https://raw.githubusercontent.com/selectel/kubernetes-examples/master/deployments/nginx-1.15.yaml --record=true
The output gives us two revisions: the first is the Deployment object we initially created, the second is the update. Since we used the –record argument during the update, we can see the command that created the second Deployment revision.
To roll back the application, we use the following command:
$ kubectl rollout undo deployment nginx-deployment --to-revision=1
In the same way that we monitored the update process, we can keep an eye on the rollback:
$ kubectl rollout status deployment nginx-deployment Waiting for rollout to finish: 6 out of 10 new replicas have been updated…
In all of our examples, we used containers without persistent storage. In the next section, we will look at how this can be done.
Data Storage
By default, all data on containers launched in Pods are ephemeral and will be lost if a pod crashes.
To launch pods with persistent data storage, we can use the PersistentVolumeClaim object.
Creating this object in a cluster is fairly simple: just add its description the same way we created pods and Service and Deployment objects in the previous sections.
You can find more information in the official documentation.
Example of a PersistenVolumeClaim description for a 10GB volume:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
We can attach it to our pod as a volume by updating the description of the pod with Nginx that we created earlier:
# nginx-with-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: library/nginx:1.14-alpine
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/var/www/html"
name: data
volumes:
- name: data
persistentVolumeClaim:
claimName: my-pv-claim
However, you need to define the object ‘kind’ as StorageClass to create a volume. In the Virtual Private Cloud, you can use fast, universal, or basic network volumes as permanent data storage for Kubernetes Pods.
For example, to create a StorageClass that lets you use a fast volume in the ru-1b zone, we need the following description:
# fast.ru-1b.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast.ru-1b
annotations:
storageclass.beta.kubernetes.io/is-default-class: "true"
provisioner: kubernetes.io/cinder
parameters:
type: fast.ru-1b
availability: ru-1b
Before creating the object, we delete the Deployment object we created earlier:
$ kubectl delete deployment nginx-deployment
We first create a StorageClass, which will make it the default class and be subsequently used by the PersistentVolumeClaim:
$ kubectl create -f \ https://raw.githubusercontent.com/selectel/kubernetes-examples/master/storageclasses/fast.ru-1b.yaml
We then create a PersistentVolumeClaim and pod:
$ kubectl create \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/persistentvolumeclaims/my-pv-claim.yaml \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/pods/nginx-with-volume.yaml
Afterwards, a volume will be automatically created in our project and connected to one of the minions in the cluster. If it crashes, the volume will automatically be mounted to another node.
We can see the volume in our Nginx container:
$ kubectl exec -it nginx sh mount | grep "/var/www/html" /dev/sdc on /var/www/html type ext4 (rw,seclabel,relatime,data=ordered) exit
You can attach volumes to Deployment objects as well. For an example of this, please look at the official documentation.
Kubernetes Dashboard
You can use the Kubernetes integrated dashboard to view and manage cluster objects.
To gain full access to the dashboard, you will have to create an administrator account in your cluster.
For this, we will need an account description:
# admin-user.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system
And a role description:
# cluster-admin.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system
Then we create these objects:
$ kubectl create \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/accounts/admin-user.yaml \ -f https://raw.githubusercontent.com/selectel/kubernetes-examples/master/clusterrolebindings/cluster-admin.yaml
Next you will need the token generated for this account.
To do this, we will have to find the relevant Secret object type in the cluster:
$ kubectl get secret --namespace=kube-system | grep "admin-user-token" admin-user-token-bkfhb kubernetes.io/service-account-token 3 22m
To view the token value in this Secret object with the name admin-user-token-bkfhb:
$ kubectl describe secret admin-user-token-bkfhb --namespace=kube-system | grep "token:" token: XXXXXX...
The response will contain the token volume. Save it as you will need it later. More information about limiting access to Kubernetes objects can be found in the official documentation.
If you created a cluster from a public template, there will already be a pod and Service powering the dashboard:
$ kubectl get svc kubernetes-dashboard --namespace=kube-system 206ms Tue Jun 19 14:35:19 2018 NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes-dashboard ClusterIP 10.254.122.245 <none> 443/TCP 2d $ kubectl get pod --namespace=kube-system --selector k8s-app=kubernetes-dashboard 119ms Tue Jun 19 14:36:48 2018 NAME READY STATUS RESTARTS AGE kubernetes-dashboard-747575c864-jpxvt 1/1 Running 0 2d
Since Service type is CusterIP, it will only be available from within the cluster. You can access the dashboard from your computer with the cluster configuration file using kubectl:
$ kubectl proxy Starting to serve on 127.0.0.1:8001
Check the proxy by opening the given address in the browser:
If your browser looks like the screenshot above, then you can open the dashboard using the following address:
http://127.0.0.1:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/
After entering this address, you should see the dashboard login screen:
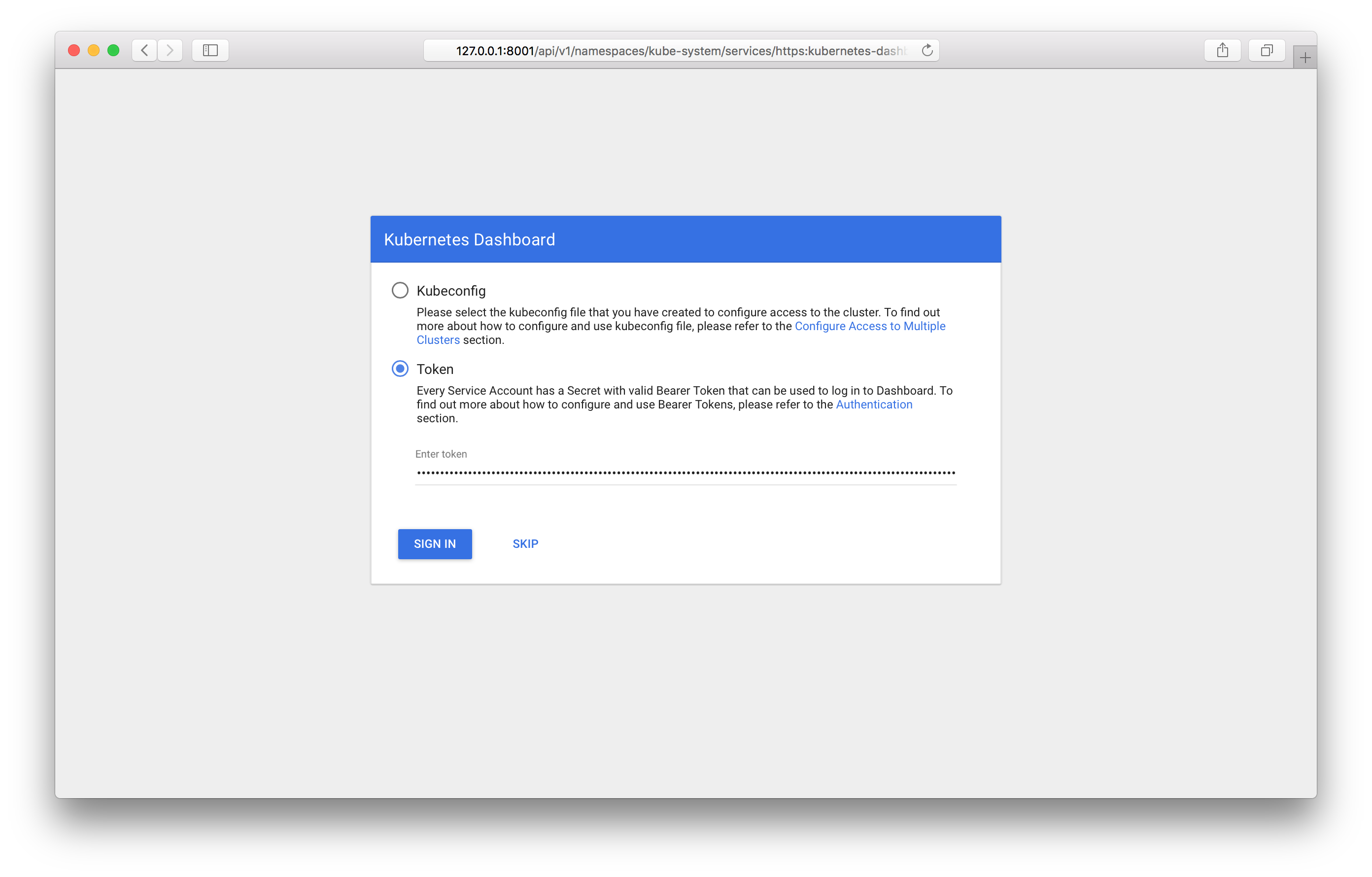
You will have to enter the token you received earlier. After logging in, you will have full dashboard access.
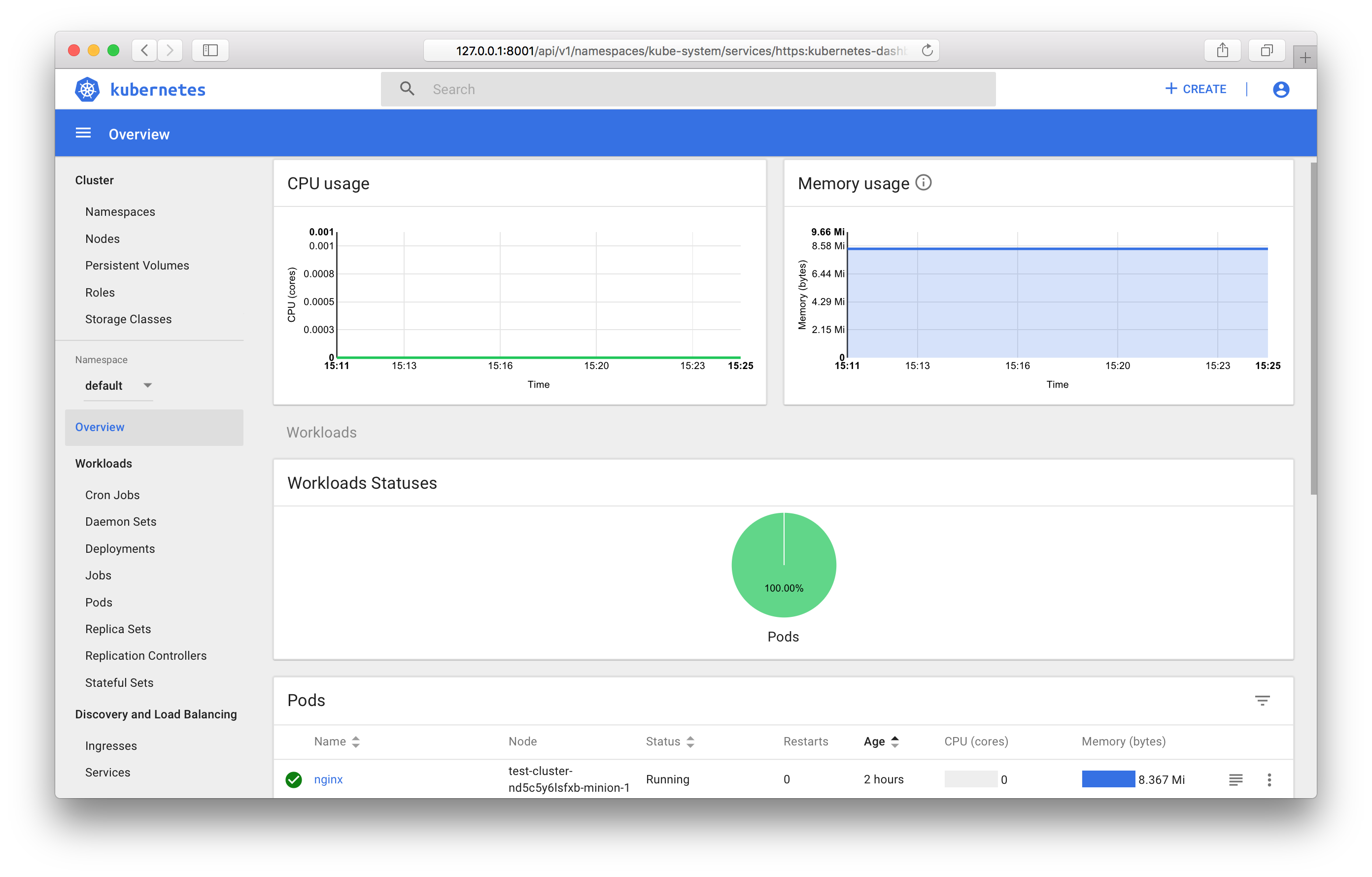
You can find more information about all of the functions available in the dashboard in the official documentation.
Monitoring Kubernetes Objects
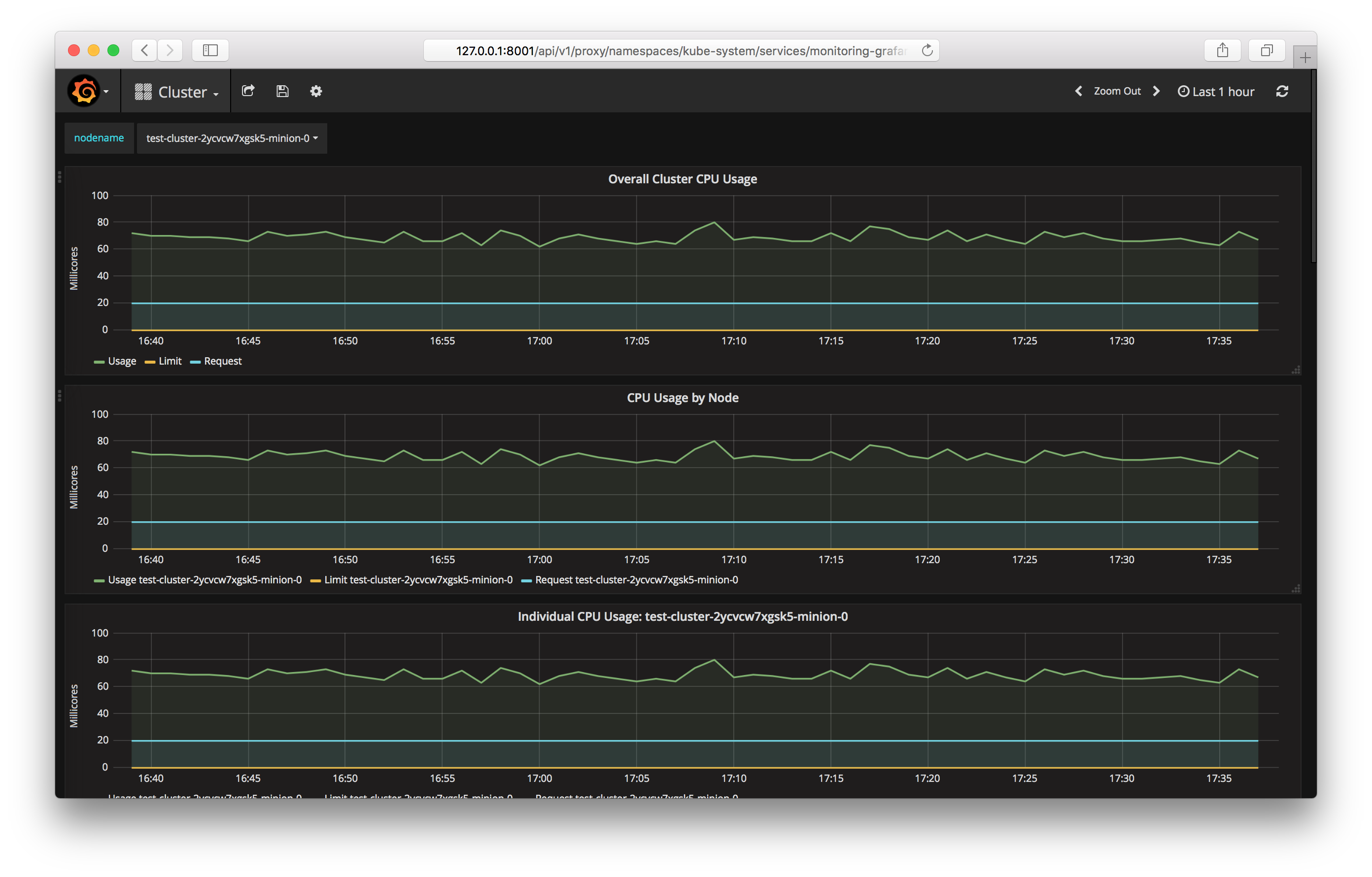
If you use a public cluster template, components for collecting and displaying metrics, Prometheus and Grafana, will be launched automatically.
Similar to the dashboard, ClusterIP is installed as a Service type. This can only be accessed from within the cluster or by using kubectl proxy. You can access Grafana from your computer at the following address:
http://127.0.0.1:8001/api/v1/proxy/namespaces/kube-system/services/monitoring-grafana:80
Conclusion
In this article, we looked at the most commonly used Kubernetes objects and saw examples of how to launch and manager clusters using OpenStack Magnum.
In the near future, it will be possible to use the latest Kubernetes releases and manage clusters from the my.selectel.ru control panel.
As always, we would be happy to hear your feedback in the comments below.