Deep into the Kernel: An Introduction to LTTng

In our previous article, we explored problems tracing and profiling the Linux kernel.
Today, we’d like to revisit these issues and talk about an interesting kernel tracer, LTTng, which was developed by Canadian programmer and researcher Mathieu Desnoyers. With this tool, we can receive information on events that occur in both the kernel and user spaces.
LTTng can be used to perform the following tasks (although this is far from the full list):
- analyze interprocess interactions in the system
- analyze application-kernel interactions in the user space
- measure the amount of time the kernel spends serving application requests
- analyze how the system works under heavy workloads
LTTng has long been included in the most official Linux repositories. It’s used by companies such as Google, Siemens, and Boeing.
In this article, we’ll be looking at the principles behind LTTng and show you how it can be used to trace kernel functions.
A Brief History
In our last article, we took a detailed look at tracepoints and some samples of code, but we never mentioned that the tracepoints mechanism was created while LTTng was being developed.
In 1999, an IBM employee, Karim Yaghmour, started working on LTT (Linux Trace Toolkit). LTT was build on the following idea: to statically instrument the most important fragments of the kernel’s code and thus effectively retrieve information on system performance. Several years later, this idea was taken over and developed by Mathieu Desnoyers as part of the LTTng (Linux Tracing Tool New Generation) project. LTTng was first released in 2005.
There’s a reason the project title includes the term New Generation: Desnoyers invested a lot in developing the Linux tracing and profiling mechanisms. He added static instrumentation for the most important kernel functions; that’s how we got the kernel markers mechanism, the improvement of which led to the development of tracepoints. LTTng actively uses tracepoints. It’s because of this mechanism that we can trace without putting additional loads on the system.
In 2009, Desnoyers defended his dissertation on the work that was done.
Mathieu Desnoyers is dedicated full time to improving LTTng. The latest stable version today, ver. 2.9, was last updated on March 14, 2017 and can be downloaded here.
Installation
LTTng is included in Linux repositories and can be installed following the standard method. In newer versions of popular distributions (such as Ubuntu 16.04), the default version is 2.7:
$ sudo apt-get install lttng-tools lttng-modules-dkms
If you are using an older version of Linux, you will need to add the PPA repository before installing LTTng 2.7 and up:
$ sudo apt-add-repository ppa:lttng/ppa $ sudo apt-get update $ sudo apt-get install lttng-tools lttng-modules-dkms
The lttng-tools package contains the following utilities:
- babeltrace – a tool for viewing trace outputs in CTF (Common Trace Format)
- lttng-sessiond – the tracing manager daemon
- lttng-consumerd – the daemon that collects data and writes it to the ring buffer
- lttng-relayd – the daemon that transfers data over a network
The lttng-modules-dkms package includes many kernel modules that can be used to interact with integrated tracing and profiling mechanisms. You can view the full list of modules by running the command:
$ lsmod |grep lttng
We can arguably divide all of these modules into three groups:
- modules for working with tracepoints
- modules for working with the ring buffer
- module probes for dynamically tracing the kernel
The LTTng-UST package is also available in the official repository and can be used to trace events in the user space. We won’t cover this in this article, but anyone interested should read this article, which serves as a good introduction to the topic.
All LTTng commands should be run by either the root user or any user included in the special tracing group (which is automatically created during installation).
Key Concepts: Sessions, Events, and Channels
The interaction process between all LTTng components is visualized in the following graph:
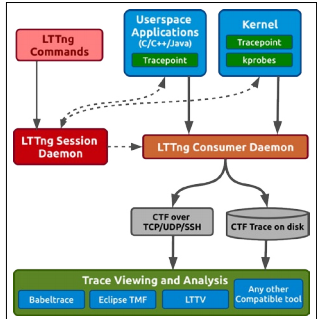
To better understand how this all works, let’s take a minute to explore the key concepts.
As we stated above, LTTng traces based on static and dynamic code instrumentation.
While instrumenting code, special probe functions are called, which read the session status and write information about events to channels.
What are sessions and channels? Sessions are tracing procedures with user-defined parameters. The graph above shows only one session, but LTTng can launch several sessions simultaneously. At any given time, you can stop a session, change its configuration, and then launch it again.
Sessions use channels to send troubleshooting data. Channel are sets of events with defined attributes and additional contextual information. These attributes (which we’ll describe in more detail below) include: buffer size, trace mode, and the switch timer period.
So why do we need channels? Mostly to support the shared ring buffer, where events are written during tracing and where the consumer daemon collects them from. The ring buffer is divided into identically sized sub-buffers. LTTng writes event data to a sub-buffer until it is full, and then moves on to write data to the next one. Data from full sub-buffers gets locked by the consumer daemon and saved to the disk (or transferred over the network).
It would be great if sub-buffers were always available for writing data, but this isn’t the case; sometimes all of the sub-buffers fill up before the consumer daemon can get to them. So what happens then? The official documentation says flat out that LTTng favors performance over integrity: it’s better to lose some event records than slow down the system. When creating a channel, you can choose one of two options (modes) for what to do when no free sub-buffer is available (event loss mode):
- discard mode – new events won’t be written until a section becomes available
- overwrite mode – the oldest events will be deleted and replaced with new ones
You can find more detailed information on configuring channels here.
Tracing Events
Now let’s move from theory to practice and launch our first tracing session.
We can view a list of currently traceable events by running the following command (we’ll only show a fragment from the output; the actual list is much bigger):
$ lttng list --kernel
Kernel events:
-------------
writeback_nothread (loglevel: TRACE_EMERG (0)) (type: tracepoint)
writeback_queue (loglevel: TRACE_EMERG (0)) (type: tracepoint)
writeback_exec (loglevel: TRACE_EMERG (0)) (type: tracepoint)
writeback_start (loglevel: TRACE_EMERG (0)) (type: tracepoint)
writeback_written (loglevel: TRACE_EMERG (0)) (type: tracepoint)
writeback_wait (loglevel: TRACE_EMERG (0)) (type: tracepoint)
writeback_pages_written (loglevel: TRACE_EMERG (0)) (type: tracepoint)
…….
snd_soc_jack_irq (loglevel: TRACE_EMERG (0)) (type: tracepoint)
snd_soc_jack_report (loglevel: TRACE_EMERG (0)) (type: tracepoint)
snd_soc_jack_notify (loglevel: TRACE_EMERG (0)) (type: tracepoint)
snd_soc_cache_sync (loglevel: TRACE_EMERG (0)) (type: tracepoint)
Let’s try to track an event—sched_switch. First, we create a session:
$ lttng create test_session Session test_session created. Traces will be written in /user/lttng-traces/test_session-20151119-134747
Our session has been created. All of the data collected during this session will be written to the file /user/lttng-traces/test_session-20151119-134747. Next, we activate the event we’re interested in:
$ lttng enable-event -k sched_switch Kernel event sched_switch created in channel channel0
Then we run:
$ lttng start Tracing started for session test_session $ sleep 1 $ lttng stop
Information about all sched_switch events will be saved in a separate file. We can view its contents by running:
$ lttng view
The events list will be huge. Moreover, it will simply contain too much information. We’ll try to hone our request to retrieve information only on events that occurred while the sleep command was running:
$ babeltrace /user/lttng-traces/test_session-20151119-134747 | grep sleep
[13:53:23.278672041] (+0.001249216) luna sched_switch: { cpu_id = 0 }, { prev_comm = "sleep", prev_tid = 10935, prev_prio = 20, prev_state = 1, next_comm = "swapper/0", next_tid = 0, next_prio = 20 }
[13:53:24.278777924] (+0.005448925) luna sched_switch: { cpu_id = 0 }, { prev_comm = "swapper/0", prev_tid = 0, prev_prio = 20, prev_state = 0, next_comm = "sleep", next_tid = 10935, next_prio = 20 }
[13:53:24.278912164] (+0.000134240) luna sched_switch: { cpu_id = 0 }, { prev_comm = "sleep", prev_tid = 10935, prev_prio = 20, prev_state = 0, next_comm = "rcuos/0", next_tid = 8, next_prio = 20 }
The printout contains information about all of the sched_switch events that were registered in the system kernel during the session. It contains several fields. The first field is the time metric, the second is the delta (time between the previous and current event). The cpu_id field shows the CPU number the event was registered for. This is followed by additional contextual information.
Upon completing our trace, we need to delete the session:
$ lttng destroy
Tracing System Calls
The lttng enable-event command has special options for tracing system calls: syscall. In our article on ftrace, we looked at an example where the chroot system call was traced. We’ll try to the same thing with LTTng:
$ lttng create $ lttng enable-event -k --syscall chroot $ lttng start
We create an isolated environment with the chroot command and then run:
$ lttng stop
$ lttng view
[12:05:51.993970181] (+?.?????????) andrei syscall_entry_chroot: { cpu_id = 0 }, { filename = "test" }
[12:05:51.993974601] (+0.000004420) andrei syscall_exit_chroot: { cpu_id = 0 }, { ret = 0 }
[12:06:53.373062654] (+61.379088053) andrei syscall_entry_chroot: { cpu_id = 0 }, { filename = "test" }
[12:06:53.373066648] (+0.000003994) andrei syscall_exit_chroot: { cpu_id = 0 }, { ret = 0 }
[12:07:36.701313906] (+43.328247258) andrei syscall_entry_chroot: { cpu_id = 1 }, { filename = "test" }
[12:07:36.701325202] (+0.000011296) andrei syscall_exit_chroot: { cpu_id = 1 }, { ret = 0 }
We see that the printout contains information on all syscall instances entering and leaving the system.
Dynamic Tracing
Above, we looked at examples of static tracing using tracepoints.
We can also use the dynamic tracing mechanism kprobes (short for kernel probes) to track events in Linux. This lets you add new tracepoints (probes) to the kernel on the fly. kprobes is what the well-known tool SystemTap is based on. It works like this: to add a probe to the kernel, we first have to write a script in a C-like language. This script will then be translated into a C code, which will be compiled in a separate kernel module. Actually using this tool can be extremely complicated.
Ftrace has supported kprobes since kernel v. 3.10. This makes it possible to run dynamic traces without writing scripts or adding new modules.
Kprobes is also supported by LTTng. Two kinds of probes are supported: native kprobes (“basic” probes that can be planted anywhere in the kernel) and kretprobes (which are planted before the function exits and grant access to its results). We’ll look at a few practical examples.
Basic probes can be set in LTTng using the probe option:
$ lttng create $ lttng enable-event --kernel sys_open --probe sys_open+0x0 $ lttng enable-event --kernel sys_close --probe sys_close+0x0 $ lttng start $ sleep 1 $ lttng stop
The trace printout should look like the following (below is only a small fragment):
…..
[12:45:26.842026294] (+0.000028311) andrei sys_close: { cpu_id = 1 }, { ip = 0xFFFFFFFF81209830 }
[12:45:26.842036177] (+0.000009883) andrei sys_open: { cpu_id = 1 }, { ip = 0xFFFFFFFF8120B940 }
[12:45:26.842064681] (+0.000028504) andrei sys_close: { cpu_id = 1 }, { ip = 0xFFFFFFFF81209830 }
[12:45:26.842097484] (+0.000032803) andrei sys_open: { cpu_id = 1 }, { ip = 0xFFFFFFFF8120B940 }
[12:45:26.842126464] (+0.000028980) andrei sys_close: { cpu_id = 1 }, { ip = 0xFFFFFFFF81209830 }
[12:45:26.842141670] (+0.000015206) andrei sys_open: { cpu_id = 1 }, { ip = 0xFFFFFFFF8120B940 }
[12:45:26.842179482] (+0.000037812) andrei sys_close: { cpu_id = 1 }, { ip = 0xFFFFFFFF81209830 }
This printout includes the ip field, which shows the IP address of the function traced in the kernel.
With the –function option, we can plant a dynamic probe at the entry and exit of a function, for example:
$ lttng enable-event call_rcu_sched -k --function call_rcu_sched
.....
[15:31:39.092335027] (+0.000000742) cs31401 call_rcu_sched_return: { cpu_id = 0 }, { }, { ip = 0xFFFFFFFF810E7B10, parent_ip = 0xFFFFFFFF810A206D }
[15:31:39.092398089] (+0.000063062) cs31401 call_rcu_sched_entry: { cpu_id = 0 }, { }, { ip = 0xFFFFFFFF810E7B10, parent_ip = 0xFFFFFFFF810A206D }
[15:31:39.092398883] (+0.000000794) cs31401 call_rcu_sched_return: { cpu_id = 0 }, { }, { ip = 0xFFFFFFFF810E7B10, parent_ip = 0xFFFFFFFF810A206D }
There’s another field in this example—parent_ip—which is the IP address of the parent that called the traced function.
We’ve only looked at some basic examples. LTTng can do much more: by combining different instrumentation capabilities, we can easily retrieve system performance information, which would be difficult or even impossible to get with other tools. You can find more details and examples of this in this article on LWN.net.
Conclusion
LTTng is an interesting with a lot of potential. Since one article is not enough to describe all of its capabilities, we would appreciate any comments or additions.
And if you’ve used LTTng yourself, please share your experience in the comments below.
For anyone who wants to learn more about LTTng, please follow the links below to other interesting materials:
- https://lttng.org/docs/ – official LTTng documentation
- http://mdh.diva-portal.org/smash/get/diva2:235301/FULLTEXT101 – a study on the efficiency of LTTng in a multicore enviroment, contains many interesting technical details
- https://sourceware.org/ml/systemtap/2011-q1/msg00244.html – performance comparison of LTTng and SystemTap
- https://events.linuxfoundation.org/slides/2011/lfcs/lfcs2011_tracing_goulet.pdf – presentation on event tracing in user space